苹果新AI模型长视频理解夺冠,小至1B版本也领先对手
发布时间:2025-09-03 09:08:23 来源:AI视频贴吧
8月23日消息,科技媒体9to5Mac今天发布博文,报道称苹果研究团队开源SlowFast-LLaVA-1.5长视频多模态大语言模型,在1B、3B、7B参数规模下,均刷新LongVideoBench、MLVU等SOTA基准纪录。
援引博文介绍,当前大语言模型在处理和理解视频方面,通用做法是在AI预训练中集成视频感知,但这种做法存在以下3重局限性:
现有模型往往严重依赖长上下文窗口,而处理时通常会遇到大量冗余帧,易超出上下文窗口限制,从而丢失信息。
大多数训练需要复杂的多阶段训练管道(通常使用私有数据集),难以重现。
许多模型仅针对视频任务优化,限制了在图像的理解,从而降低通用模型的实用性。
苹果公司针对上述3个局限性,首先研究推出了SlowFast-LLaVA开源模型,最大的亮点是创新双流(two-stream)设置,其中“慢流”选取少量高分辨率帧捕捉场景细节,“快流”选取更多低分辨率帧追踪运动变化。
苹果进一步在开源模型SlowFast-LLaVA模型上,通过微调图像模型,进一步增强视觉推理能力,再联合图像与视频训练,保留图像理解优势,推出了SlowFast-LLaVA-1.5版本。
在设计上,SF-LLaVA-1.5将输入视频帧数固定为128,其中快流96帧,慢流32帧,适配各种时长视频。这种方法虽可能漏掉关键帧或影响播放速度判断,但显著降低了计算和显存需求。研究团队指出,可通过引入内存优化技术(如随机反向传播)进一步改进,但需解决高显存占用问题。
测试显示,该模型在长视频基准LongVideoBench、MLVU上均取得新纪录,而且1B版本也能领先竞争对手。同时,它在知识问答、数学推理、OCR等图像相关任务上表现出色,实现视频与图像的通用理解能力。
该项目完全基于公开数据集训练,方便学术与产业复现,并已在GitHub与HuggingFace开源。
热门推荐






-

苹果新AI模型长视频理解夺冠,小至1B版本也领先对手
科技媒体9to5Mac今天发布博文,报道称苹果研究团队开源SlowFast-LLaVA-15长视频多模态大语言模型,在1B、3B、7B参数规模下,均刷新LongVideoBench、M
2025-09-03
-
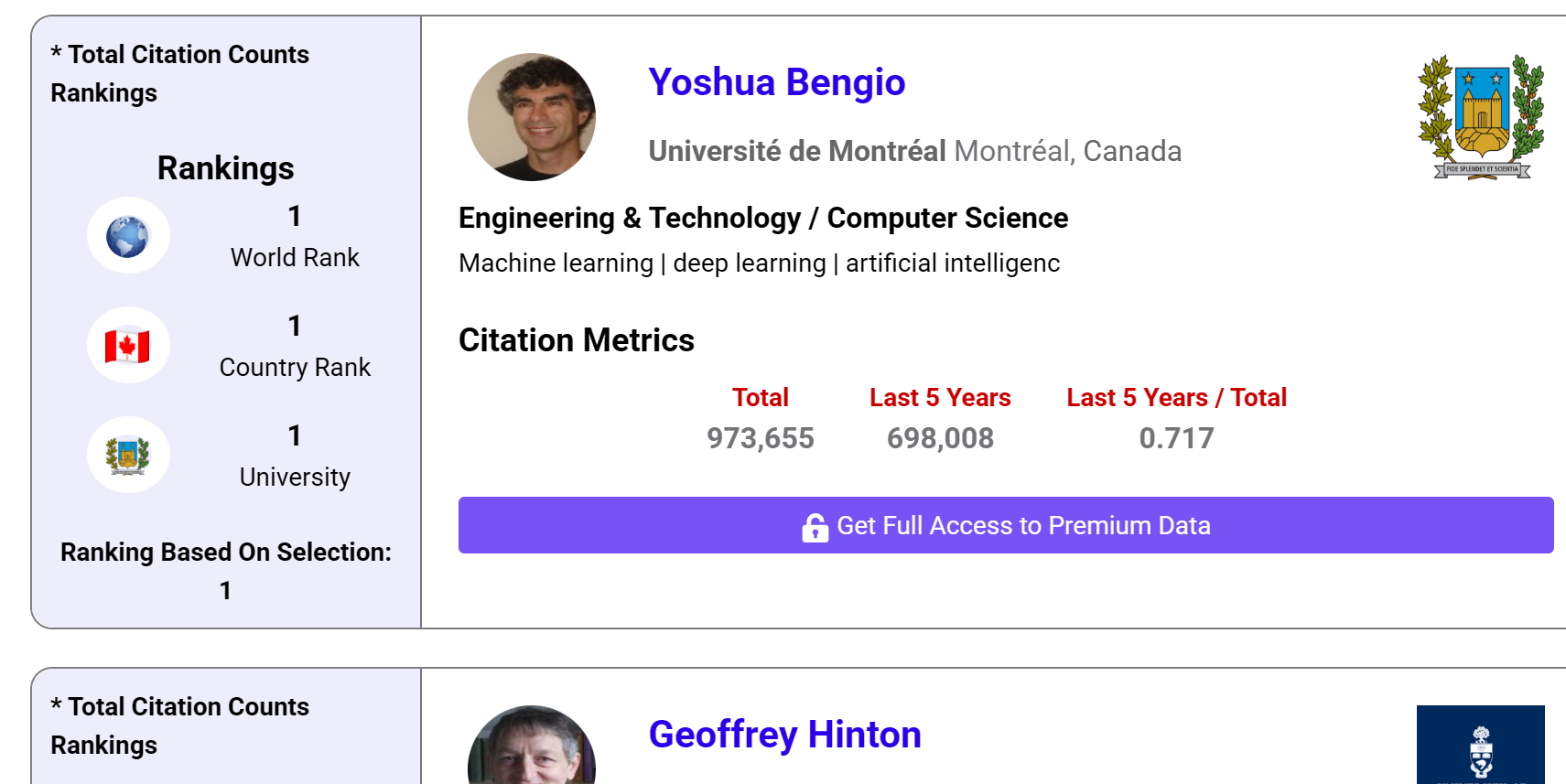
科学界论文高引第一人易主!AI站上历史巅峰
图灵奖得主YoshuaBengio,论文总引95万+魔镜魔镜,谁是有史以来被引用次数最多的科学家?答案:深度学习三巨头之一、图灵奖得主YoshuaBengio。
2025-09-03
-

钉钉发布8.0版本:推出下一代AI办公应用形态钉钉ONE
8月25日消息,今日,钉钉发布80版本,推出了下一代AI办公应用形态:钉钉ONE。钉钉ONE被设计为人与AI通过自然语言对话的统一入口,致力于打造全球首个以Agent驱动的工作信息流,让工作处
2025-09-03
-

马斯克成立新公司「巨硬」:用AI把微软产品重做一遍
论搞事情,还得是你马斯克。这不,为了硬刚微软,老马直接成立了一家新公司——巨硬(Macrohard)。就冲这个名字哈,那可真叫一个贴脸开大。不论是中文还是英文角
2025-09-03
-

AI演进:推动5G与Wi-Fi连接方式的变革
要点:通过高通X855G调制解调器及射频和高通FastConnect7900移动连接系统支持的AI连接技术,蜂窝网络与Wi-Fi网络之间可实现无缝切换,从而提升游戏和视频通话等应用的实时性能表现。
2025-09-03